TSDB 的一些特点:
- 一般使用 KV 存储模型,检索的要素都保存在 key 中;
- TSDB 常用于存储监控数据,其中监控的指标称为“metric”,以及多个 k=v 格式的标签(一般称为 label or tag ),例如 service=service1, ip=10.10.2.58,以及时间戳
例如 Prometheus 的 Key 设计为 http_request_total{status=200,method="GET"}@timestamp 的格式
OpenTSDB schema 设计
Overview
OpenTSDB 是基于 HBase 设计的,架构设计如下:
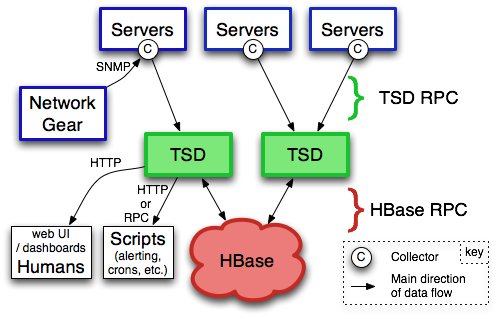
- 图中 TSD 即为(对应实际进程名是 TSDMain) opentsdb 组件。每个实例 TSD 都是独立的。没有 master,没有共享状态(shared state),因此实际生产部署可能会通过 nginx+Consul 运行多个 TSD 实例以实现负载均衡;
- Server 通过 TSD RPC 向 TSD 上报数据,TSD 则通过 HBase RPC 与 HBase 进行通讯;
行键的设计
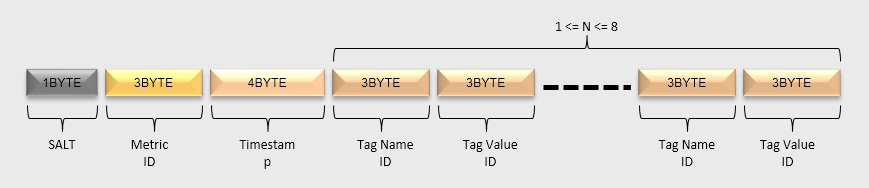
OpenTSDB 的 Rowkey 格式为: [salt]<metric_uid><timestamp><tagk1><tagv1>[...<tagkN><tagvN>]
- SALT: 为了充分利用 HBase 分布式 Region Server 的能力,SALT 可以有效避免 HBase 的写入热点问题,开启 SALT 后,会对创建的 HBase Scanner 数量有影响,HBase Scanner 数量等于 SALT 的数量;
- Metric:监控指标名,例如 “sys.cpu.user”
- timestamp:小时级时间戳
- TagK-TagV:由多个标签的 KV 对构成,例如 “ip=10.10.2.58 core=0”
所以一个 Rowkey 的逻辑值看起来如下: sys.cpu.user 1541946115 ip=10.10.2.58 core=0
OpenTSDB 为了减少 Rowkey 的空间占用,Metric、Tag 等都使用 UID(Unique ID)来代替,UID 默认占用3字节,UID 占用字节数可以通过参数调整,
OpenTSDB 为每种 Metric、TagK、TagV 都生成一个 UID,Metric、TagK、TagV 各自拥有自己的 UID 空间,换句话说所有 Metric 的 UID 不会出现重复,但 Metric 和 TagK 之间可能有重复的 UID;
我们可以通过分别修改 tsd.storage.uid.width.metric、tsd.storage.uid.width.tagk 以及 tsd.storage.uid.width.tagv 参数来设置对应编码占用的字节数。
所以 Rowkey 实际占用空间如下所示:
列的设计
由于 Rowkey 中已经包含了小时级的时间戳,所以需要通过列名(Qualifier)存储相对秒数(或毫秒数)
(1)当 OpenTSDB 接收到一个新的 DataPoint 的时候,如果请求中的时间戳是秒,那么列名(Qualifier)将占用 2字节:
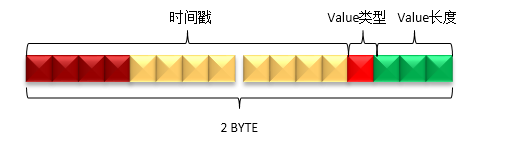
- 低3位表示 Value 的长度,Value 的长度 = (qualifier & 0x07) + 1
- 中间1位表示 Value 的类型,如果值为1,表示 Value 的类型为 float;如果值为0,表示 Value 的类型为 long。
- 高12位表示相对于 Rowkey 中小时级时间戳的秒数,最大为 3600
判断请求中的时间戳为秒或毫秒的方法是基于时间戳数值的大小,如果时间戳的值的超过无符号整数的最大值(即4个字节的长度),那么该时间戳是毫秒,否则为秒
(2)如果 OpenTSDB 收到的 DataPoint 时间戳是毫秒,那么列名(Qualifier)将占用 4字节:

- Value 长度:与秒级时间戳相同;
- Value 类型:与秒级时间戳相同;
- 用22位表示相对于 Rowkey 中小时级时间戳的毫秒数
- 高4位是(标志位)固定全为1;
表的设计
由于每种 Metric、TagK、TagV 都被映射为一个 UID,所以 OpenTSDB 还需要一张额外的表存储 UID:
(1)表 tsdb:所有的时序数据都存于这张表,Rowkey = [SALT] <metric> <小时级时间戳> <TagK1> <TagV1> ...,列族只有一个 t,列名为数据的时间戳相对于 Rowkey 中小时级时间戳的秒数(or 毫秒数),一个 CF:Qualifier 例如 t:3600

(2)表 tsdb-uid:opentsdb 会将每种 metric、tagk、tagv 都映射成 UID,映射是双向的,比如说既可以根据 tagk 找到对应的 UID,也可以根据 UID 直接找到相应的 tagk。而这些映射关系就记录在 tsdb-uid 表中。该表有两个 ColumnFamily,分别是 name 和 id,另外这两个 ColumnFamily 下都有三列,分别是 metric、tagk、tagv。如下图所示:

Reference
百度自研 TSDB
- 底层存储使用 HBase;
- RowKey = entity_id + metric_id + timebase
- entity_id 是由 tagK 和 tagV 经过 hash 得到的一个固定长度的值,hash 后原始字符串的自然顺序被打乱,使得 RowKey 能够相对均匀地分布在不同 HRegion 中;
- metric_id 为 metric 的字符串 hash 值,同样是固定长度;
- timebase 为 Unix 时间戳按照 1 小时(3600 秒)取整得到的数值,固定 4 个字节的长度
- Column: 列名使用相对 Rowkey 小时级时间戳的秒数;
参考: